1. A100:數(shù)據(jù)中心AI計算的奠基石
A100是英偉達2020年發(fā)布的旗艦級數(shù)據(jù)中心GPU,基于Ampere架構(gòu),主要特性包括:
-
-
-
-
-
-
-
應(yīng)用場景:深度學(xué)習(xí)訓(xùn)練、推理、科學(xué)計算、大規(guī)模數(shù)據(jù)分析
A100可廣泛應(yīng)用于高性能計算(HPC)和深度學(xué)習(xí)任務(wù),適用于需要大量計算資源的企業(yè)級用戶。
2. H100:性能提升的算力*
H100是A100的升級版,采用更*的Hopper架構(gòu),相比A100提升了數(shù)倍的計算性能,主要特性包括:
-
-
-
-
顯存:80GB HBM3(帶寬高達3.35TB/s)
-
-
Transformer Engine:專門優(yōu)化AI大模型訓(xùn)練,如GPT-4
-
應(yīng)用場景:大規(guī)模AI訓(xùn)練、HPC、企業(yè)級AI推理
H100特別適用于大型AI模型訓(xùn)練,比如Llama、GPT、Stable Diffusion等,可以大幅提升訓(xùn)練效率。
3. A800 & H800:*市場*版
A800和H800是英偉達專為*市場推出的受限版GPU,以符合美國的出口管制要求:
-
A800:基于A100,限制了NVLink互聯(lián)帶寬,適合AI推理和訓(xùn)練
-
H800:基于H100,限制了帶寬,但仍然保留了較高的計算能力,適用于大型AI訓(xùn)練
這些GPU主要面向*客戶,如阿里云、騰訊云、百度云等云計算廠商,性能稍遜于A100和H100,但仍然具備極高的計算能力。
4. H20:新一代受限算力GPU
H20是英偉達為*市場設(shè)計的新一代受限版H100,預(yù)計將取代H800:
H20仍然具備強大的算力,適用于AI訓(xùn)練和推理,但具體性能指標(biāo)需等待正式發(fā)布后確認(rèn)。
二、如何搭建自己的算力中心?
如果你想搭建自己的算力中心,無論是用于AI訓(xùn)練,還是進行高性能計算,都需要從以下幾個方面考慮:
1. 確定算力需求
首先需要明確你的算力需求:
-
AI訓(xùn)練:大規(guī)模深度學(xué)習(xí)訓(xùn)練(如GPT、Transformer)推薦H100或H800
-
AI推理:推薦A100、A800,推理對帶寬要求較低
-
科學(xué)計算 & HPC:H100*優(yōu),A100次之
-
中小規(guī)模計算:可以考慮A800、H800或H20
2. 選擇GPU服務(wù)器
你可以選擇以下方式搭建你的GPU算力中心:
-
-
-
選擇如 DGX Station A100/H100,單機*多4-8張GPU
-
-
-
可使用 DGX A100/H100 服務(wù)器,支持多臺GPU互聯(lián)
-
通過InfiniBand和NVLink構(gòu)建大規(guī)模集群
3. 搭配高性能計算環(huán)境
-
CPU:推薦使用AMD EPYC 或 Intel Xeon 服務(wù)器級CPU
-
內(nèi)存:建議*低256GB,AI訓(xùn)練需要大量內(nèi)存
-
存儲:SSD + 高速NVMe存儲(如1PB級別)
-
網(wǎng)絡(luò):支持InfiniBand和100GbE以上高速網(wǎng)絡(luò)
4. 軟件環(huán)境搭建
-
操作系統(tǒng):Ubuntu 20.04 / 22.04 LTS,或基于Linux的服務(wù)器環(huán)境
-
驅(qū)動與CUDA:安裝*新的NVIDIA驅(qū)動,CUDA 11+(H100支持CUDA 12)
-
如果對數(shù)據(jù)隱私和持續(xù)算力需求較高,建議選擇本地搭建GPU集群。
三、訓(xùn)練場景 vs 推理場景
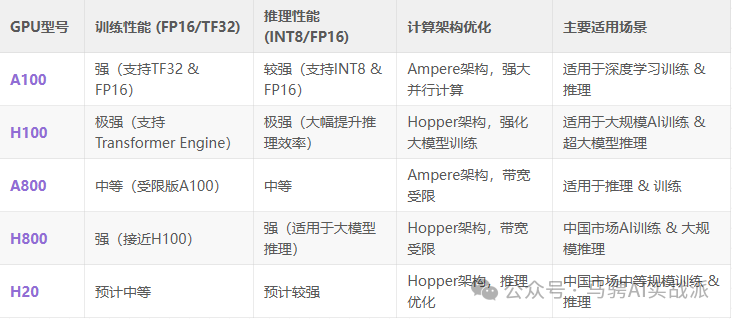
在AI訓(xùn)練(Training)和AI推理(Inference)場景下,不同GPU的性能表現(xiàn)存在明顯差異。主要區(qū)別體現(xiàn)在計算精度、帶寬需求、顯存優(yōu)化以及核心架構(gòu)等方面。以下是詳細(xì)對比:
訓(xùn)練 vs. 推理:性能對比
 image
image
訓(xùn)練 vs. 推理:性能解析
1. 計算精度(數(shù)值格式)
在AI計算中,不同的數(shù)值格式影響計算速度和精度:
-
訓(xùn)練 需要高精度計算(如 FP32、TF32、FP16)
-
推理 需要低精度計算(如 INT8、FP16),以提升計算吞吐量
H100 特別優(yōu)化了 Transformer Engine,在 FP8/FP16 下可大幅提升 AI 訓(xùn)練和推理性能,適用于 LLM(大語言模型)如 GPT-4。
2. 顯存帶寬
訓(xùn)練任務(wù) 通常需要處理大規(guī)模數(shù)據(jù),因此高顯存帶寬至關(guān)重要:
-
H100(HBM3,3.35TB/s) → 訓(xùn)練速度比 A100 快 2-3 倍
-
A100(HBM2e,1.6TB/s) → 適合標(biāo)準(zhǔn) AI 任務(wù)
-
H800/A800 由于帶寬受限,訓(xùn)練效率比 H100 低
推理任務(wù) 一般不需要大帶寬,因為:
-
數(shù)據(jù)已訓(xùn)練完成,只需加載模型進行計算
-
推理更關(guān)注 吞吐量(TPS) 和 延遲(Latency)
3. 并行計算 & 計算核心優(yōu)化
-
AI訓(xùn)練 依賴 矩陣計算(Tensor Cores),需要強大的 FP16/TF32 計算能力
-
AI推理 需要高效的 INT8/FP16 計算,以提高吞吐量
在計算核心優(yōu)化上:
|
|
|
|
|
A100
|
Tensor Core優(yōu)化,F(xiàn)P16/TF32 訓(xùn)練
|
|
|
H100
|
Transformer Engine
|
|
|
A800
|
|
|
|
H800
|
|
|
|
H20
|
|
|
H100 在 Transformer-based AI 任務(wù)(如 GPT)中比 A100 快 6 倍,而推理吞吐量也更高。
小結(jié)
-
AI訓(xùn)練: 需要高帶寬 + 高精度計算,推薦 H100/A100 及其變種
-
AI推理: 需要低延遲 + 高吞吐量,推薦 H100/H800/H20
-
H100 在Transformer模型訓(xùn)練 和 推理吞吐量 方面遙遙*
-
A100/A800 仍然是中等預(yù)算下的優(yōu)秀選擇
未來,隨著 H20 逐步普及,它可能成為*市場AI訓(xùn)練和推理的*。
四、算力中心投資成本估算
根據(jù)GPU型號,搭建算力中心的成本會有所不同:
一個基礎(chǔ)的4張H100服務(wù)器可能需要20萬-50萬美元,而大型AI訓(xùn)練集群(如64張H100)則可能超過千萬美元。
小結(jié):如何選擇合適的算力架構(gòu)?
-
預(yù)算有限? 選擇 A100、A800、H800
-
-
云端還是本地? 云端適合短期任務(wù),本地適合長期需求
-
數(shù)據(jù)隱私? 關(guān)鍵業(yè)務(wù)建議本地部署
